
The seven-week tick
OpenAI's flagship reasoning model lasted forty-nine days.
GPT-5.4 shipped on March 5, 2026.1 On April 23, the company replaced it with GPT-5.5 — internally codenamed "Spud" — alongside a higher-priced GPT-5.5 Pro. The API followed twenty-four hours later. It is the first fully retrained base model since GPT-4.5 and the centrepiece of OpenAI's promised "super app": Codex for computer-use, ChatGPT for consumers, the Atlas browser as the connective layer.2
Greg Brockman, the company's president, framed the model in a press briefing as "a new class of intelligence … being very proactive and really being able to solve problems end to end."3 Two paragraphs later, in the same briefing, he conceded what the cadence has done to public attention: "there are enough model releases that it's probably getting hard to distinguish one from another."4
Both sentences are true. They are also the entire story of this launch.

What GPT-5.5 actually does
The pitch is "real work."
OpenAI's launch post leads with this sentence: "Instead of carefully managing every step, you can give GPT-5.5 a messy, multi-part task and trust it to plan, use tools, check its work, navigate through ambiguity, and keep going."2 In practice that means three things.
Agentic coding. Inside Codex, GPT-5.5 can take a one-line prompt — "fix the failing tests in this repo and ship it" — plan a sequence of file edits, invoke a terminal, run the test suite, debug regressions, and iterate. OpenAI claims it does this with roughly forty percent fewer output tokens than GPT-5.4 for the same Codex task and at the same per-token latency.2
Computer use. A demo from OpenAI's developer account on X shows GPT-5.5 driving a virtual browser through multi-tab research, file generation, and image creation in a single autonomous run.6 On the OSWorld-Verified benchmark — a standard test of AI agents driving a real desktop — the model scores 78.7%, up from 75.0% for GPT-5.4 and roughly even with Anthropic's Claude Opus 4.7 at 78.0%.2
Knowledge work. ChatGPT now selects between three GPT-5.5 modes automatically: a default fast model, a "Thinking" reasoning model for hard questions, and a Pro model for the hardest. The Plus plan caps Thinking at 3,000 messages per week. The Go plan, OpenAI's $5 entry tier, gets a narrowly metered version — 10 messages every 5 hours — that the company describes as a tools-menu add-on rather than a default.7

The "super app" framing — TechCrunch's, not OpenAI's — captures the strategic move. Each of the four April releases handles a different surface: Images 2.0 owns generative media, Workspace Agents owns the office, the Privacy Filter owns enterprise procurement objections, and GPT-5.5 owns the brain underneath all of them.4
The benchmark sheet
OpenAI's launch table claims state-of-the-art on fourteen evaluations against Claude Opus 4.7 and Gemini 3.1 Pro Preview. The headline numbers:
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| MMLU | 92.4% | — | — | — |
| SWE-Bench Verified | 88.7% | — | — | — |
| SWE-Bench Pro | 58.6% | 57.7% | 64.3% | 54.2% |
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| GDPval (real-world) | 84.9% | 83.0% | 80.3% | 67.3% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 22.9% | 16.7% |
| ARC-AGI-2 | 85.0% | 73.3% | 75.8% | 77.1% |
| OSWorld-Verified | 78.7% | 75.0% | 78.0% | — |
| Tau2-bench Telecom | 98.0% | 92.8% | — | — |
| FinanceAgent | 60.0% | 56.0% | 64.4% | 59.7% |
| MRCR v2 (long context) | 74.0% | 36.6% | 32.2% | — |
The pattern: GPT-5.5 wins on long-context retrieval (MRCR v2 doubles), agentic coding (Terminal-Bench, OSWorld), and frontier mathematics (FrontierMath Tier 4 +8.3 points). It loses to Claude Opus 4.7 on SWE-Bench Pro and FinanceAgent — two of the more enterprise-coded tests. OpenAI's launch post adds a footnote on SWE-Bench Pro reading "evidence of memorization on this eval" — a polite suggestion that Anthropic's lead is contaminated.2
The real-world delta is smaller than the table reads. GDPval — the eval OpenAI itself describes as closest to enterprise tasks — moved from 83.0% to 84.9% in seven weeks. That is 1.9 points.2
There are enough model releases that it's probably getting hard to distinguish one from another.
The independent ledger
Within hours of the launch, two third-party benchmark teams published their own numbers. They tell a more complicated story.
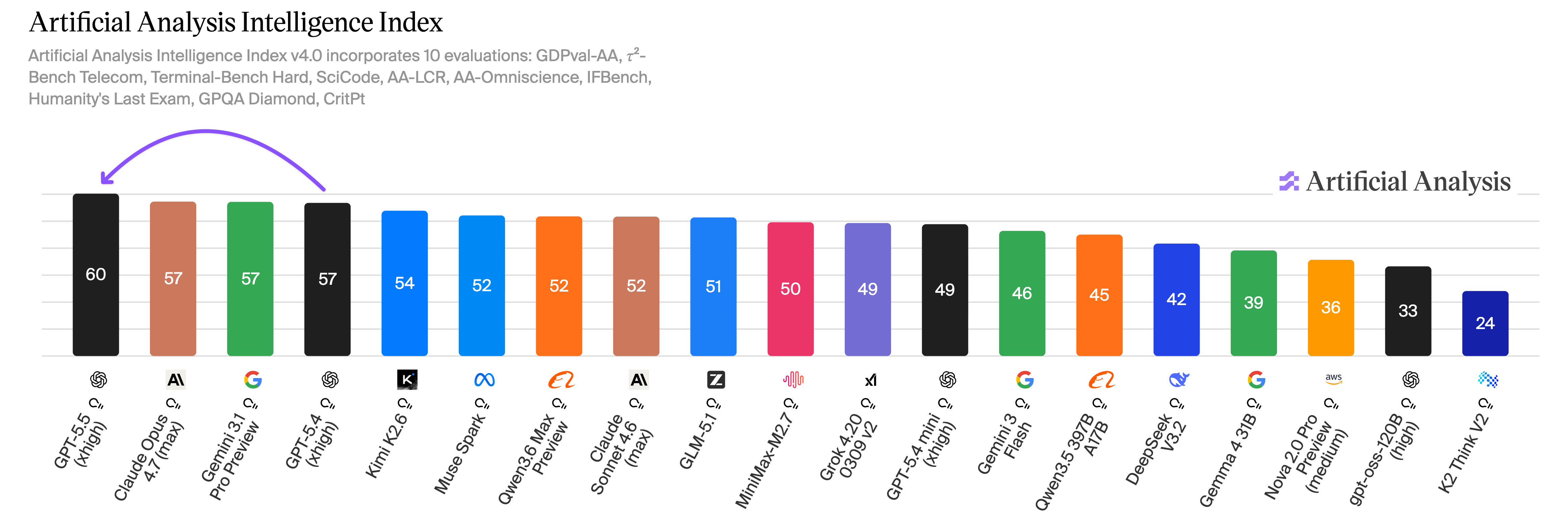
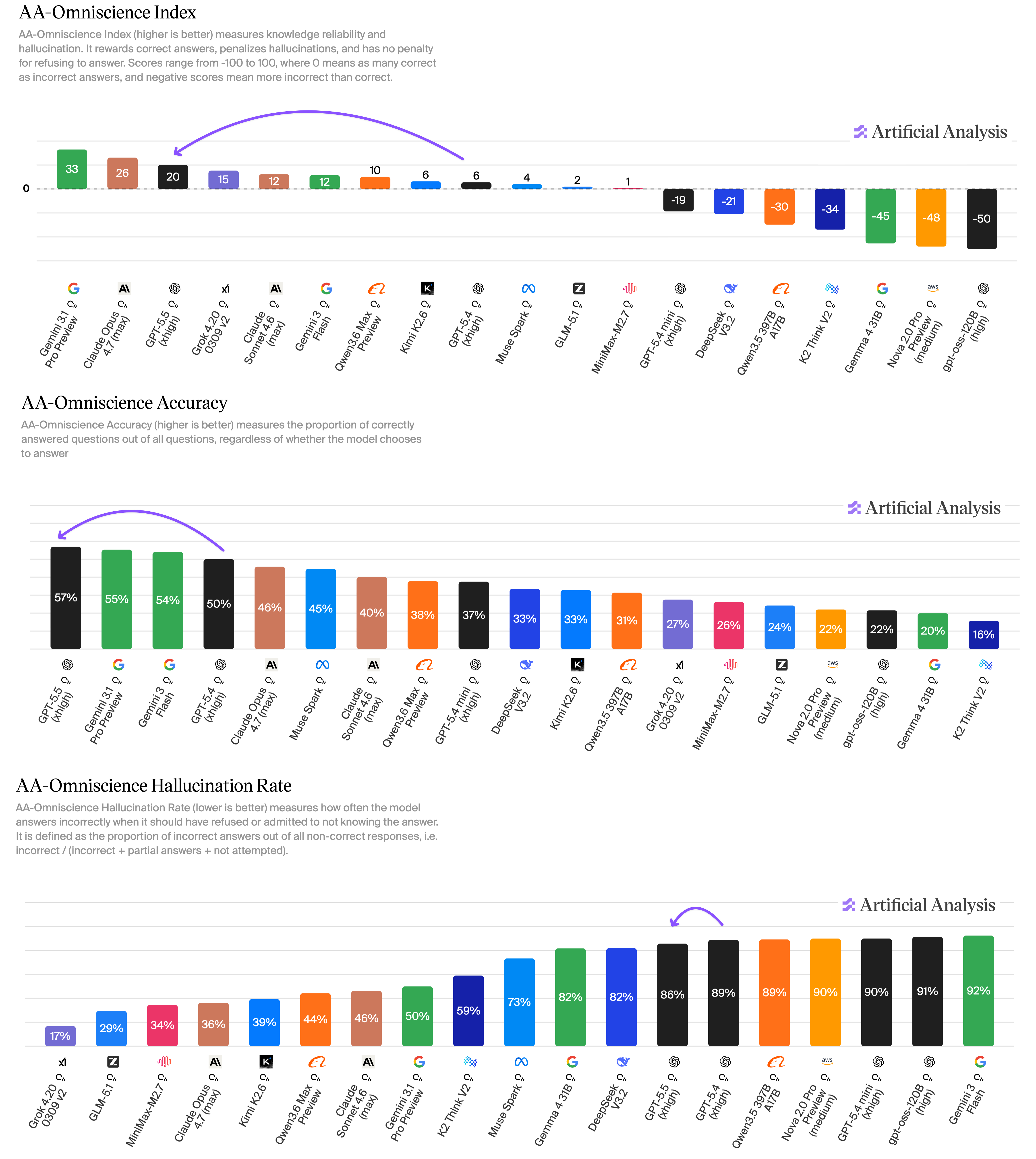
Artificial Analysis — the most-cited independent leaderboard — gave GPT-5.5 the top slot on its Intelligence Index, breaking what had been a three-way tie with Anthropic and Google.8 Then came the Omniscience score: GPT-5.5 hit 57% accuracy, the highest ever measured, alongside an 86% hallucination rate. The hallucination rate is the share of factual questions where the model produces a confident wrong answer rather than a refusal. Claude Opus 4.7 sits at 36% on the same metric. Gemini 3.1 Pro at 50%.8
OpenAI's launch post claims a roughly sixty-percent reduction in hallucinations versus GPT-5.4. Artificial Analysis's reading is the opposite: GPT-5.5 is more confident and more wrong than its peers, even as its raw knowledge improves. The two findings are not necessarily contradictory — OpenAI is measuring against its own prior models on its own evals; AA is comparing to current rivals on a public eval — but the public reader is left with two incompatible headlines.
XBOW, the security firm whose offensive-capability benchmark has tracked frontier models for two years, published its own results the same day under the headline "GPT-5.5: Mythos-Like Hacking, Open To All."9 Their measurement of vulnerability miss rate — the share of real-world security flaws the model fails to find — fell from 40% on GPT-5 to 18% on Claude Opus 4.6 to 10% on GPT-5.5.
XBOW's own framing: "With code, it's effectively killed our benchmark."9
That is good news for defenders, who get a sharper auditor. It is the opening of an obvious other door for everyone else, and OpenAI knows it: the model is rated High on cybersecurity under the company's own Preparedness Framework, one tier below Critical, the highest "released" rating to date.10
The science demos
Three set-pieces have circulated since launch.
Bartosz Naskręcki, mathematician, Adam Mickiewicz University. Single Codex prompt → working interactive visualisation of an algebraic-geometry problem in eleven minutes. Cited by Brockman in the Fortune briefing.4
Derya Unutmaz, immunologist, The Jackson Laboratory. Used GPT-5.5 Pro to analyse gene-expression data from 62 samples spanning ~28,000 genes. The output, by his account, "would have taken his team months." OpenAI claims a +6 point GeneBench gain on the Pro tier (33.2% vs. 25.6% on GPT-5.4 Pro) and a +6 point BixBench gain.2

Brandon White, co-founder, Axiom Bio. "If OpenAI keeps cooking like this, the foundations of drug discovery will change by the end of the year."2
The hedge: every named scientist on OpenAI's launch page is either an early-access partner or quoted in OpenAI's own marketing material. Independent academic responses outside the launch were quieter. Ethan Mollick, the Wharton professor whose model evaluations have framed every major AI release for two years, called GPT-5.5 "a noteworthy step along the way" — pointedly not the new class of intelligence OpenAI's president had pitched. "The jagged frontier is still there," he wrote. "It is just much further out than it used to be."11
The price doubled
GPT-5.5's most contested decision is not technical. It is on the rate card.
| Model | Input / 1M tokens | Output / 1M tokens | Cached input |
|---|---|---|---|
| GPT-5.4 (reference) | $2.50 | $15.00 | $0.25 |
| GPT-5.5 | $5.00 | $30.00 | $0.50 |
| GPT-5.5 Pro | $30.00 | $180.00 | — |
The headline rate is exactly twice GPT-5.4.12 OpenAI's defence is two-part: token efficiency cuts the average call by ~40%, and the additional capability is what enterprise customers are actually paying for. Both pieces are partially true. Artificial Analysis ran the cost numbers across its full Index and reports an effective +20% net cost increase — the efficiency absorbs about half the price hike.8
Less than thirty hours after GPT-5.5's API went live, DeepSeek previewed V4 — an open-weights frontier model — at roughly one-sixth the per-token cost of Claude Opus 4.7 and GPT-5.5.13 Kimi K2.6, released two days before GPT-5.5, holds the open-weights AA crown for total intelligence per dollar.8 OpenAI has not publicly responded to either.
The enterprise customer testimony, for now, is one-on-the-record.
That is Leigh-Ann Russell, CIO of Bank of New York, speaking to Fortune.4 She is OpenAI's flagship public quote in mainstream press coverage.

The developer side has been louder and more mixed. Cursor's Michael Truell calls the model "noticeably smarter and more persistent than 5.4."2 Theo Browne's review, posted two hours after launch, opens with "I don't really like GPT-5.5" — arguing GPT-5.4 stays the cost-efficient daily driver.14 On Hacker News, the top thread runs to 1,034 comments and reads, in summary, as: clearly stronger on coding; refusal-prone in places; instruction-fidelity over long sessions still the unresolved problem.15
The companion launches
The model did not arrive alone.

ChatGPT for Clinicians (April 22) — free for verified U.S. clinicians, with continuing medical education credits inside the product. The clearest signal yet that OpenAI is moving from horizontal consumer chatbot to vertical-by-vertical professional tooling.2

Workspace Agents (April 22) — Business and Enterprise only. The first ChatGPT surface where the model takes multi-step actions across enterprise data sources without user-initiated prompts.2

OpenAI Privacy Filter (April 22) — auto-redacts PII before model processing across all ChatGPT plans. A direct response to the procurement-blocker question every enterprise buyer has been asking for two years.2

ChatGPT Images 2.0 (April 21) — improved image-generation model, livestream-launched. Mollick used the model for an extended visual test on his Substack: an Otter portrait across multiple styles, an academic-paper synthesis image, a multi-room mood board.11 Output quality is competitive with Midjourney v7 and Adobe Firefly 3 by his read; the AI smell — the over-smoothed, plastic transitions — is still detectable.
The safety question
The release's hardest moments are not on the rate card. They are in two parallel safety storylines that broke before and after launch.

The UK AI Security Institute red-team result. Pre-launch, AISI was given access for an evaluation. The team found a universal jailbreak in six hours. AISI's published finding, summarised by Transformer News on April 24: the institute "was not able to properly run tests to verify the effectiveness of the final configuration."16 OpenAI has not publicly answered whether that jailbreak was patched in the released model. Transformer News's editorial framing: "We do not know if GPT-5.5 is actually safe to release. All we have to rely on is OpenAI's word."16
The Tumbler Ridge apology. On April 25, two days after launch, Sam Altman published a letter apologising to the community of Tumbler Ridge, British Columbia.17 OpenAI had failed to escalate to law enforcement a flagged ChatGPT user later linked to a January 2026 mass shooting in the town. "I am deeply sorry [that we] failed to alert law enforcement," Altman wrote. The apology details neither the policy gap nor the remediation. The story now runs in parallel with every GPT-5.5 review.
The Bio Bug Bounty. OpenAI is opening an external red-team program for biology safeguards from April 28 to July 27, 2026 — invite-only, NDA-bound. The Preparedness Framework rates the bio/chem capability High, the same tier as cyber. Both ratings are the highest OpenAI has ever shipped a model under.10

The combined picture is uncomfortable. OpenAI ships an offensive-security capability Anthropic deliberately gated behind its non-public Mythos preview. The UK's safety institute, the closest thing to an independent state regulator, says it could not verify the configuration. The company itself rates the bio/chem and cyber capability one tier below Critical. And — separate from the launch but consumed alongside it — the company's CEO is apologising in print for a missed escalation that may have cost lives.
Five questions OpenAI hasn't answered
Did AISI ever verify the shipped configuration?
The pre-launch jailbreak finding has not been publicly retracted, patched, or contradicted by OpenAI. The UK government's safety institute — the closest thing to a third-party regulator — is on record saying it could not verify the released model.16
Why doubled API price, given the company's own efficiency claim?
Token efficiency does not, by Artificial Analysis's measurement, absorb the rate hike. The remaining +20% is unexplained. Compute scarcity is the implicit answer; OpenAI hasn't said it.8
What happened in Tumbler Ridge, and what changed afterwards?
The apology issued on April 25 acknowledges the failure to escalate but does not detail the policy gap, the personnel decisions, or the new escalation protocol. The detail is what determines whether the apology is structural or rhetorical.17
What is the relationship between GPT-5.5, GPT-Rosalind, and the 400K-vs-1M context cap?
OpenAI introduced GPT-Rosalind, a life-sciences reasoning model, on April 16. It has not disclosed whether Rosalind is a 5.5 derivative or a separate stack. The Codex-vs-API context-window gap is undocumented.2
Is OpenAI ready for DeepSeek V4 at one-sixth the price?
A same-week open-weights competitor that delivers near-frontier capability at a fraction of the cost is the most direct attack the company has faced on its pricing model. As of this writing, OpenAI has not publicly responded.13
In the end
The cleanest reading of GPT-5.5 is not that the model is bad. It is that the cycle has broken its own framing.
OpenAI's president describes a new class of intelligence in one breath and the indistinguishability of model releases in the next. The system card rates the model's offensive-security capability High. The UK's safety institute — pre-launch — says it found a universal jailbreak in six hours. The Bank of New York's CIO says hallucination resistance is now bankable. Artificial Analysis's independent eval says hallucination rates are the worst of any frontier model on the leaderboard. The launch slide deck shows fourteen state-of-the-art benchmarks. The same slide deck shows GDPval — the closest test to enterprise tasks — moving 1.9 points in seven weeks.
All of these statements are true at the same time.
What has changed, between GPT-5.4 and GPT-5.5, is not the technology. It is the public's ability to take the releases at face value. The cadence is no longer a story of acceleration. It is a stress test of trust — between OpenAI and the regulators who can no longer verify what shipped, between OpenAI and the developers paying twice the rate for a model that reviewers say might be a daily driver, between OpenAI and the British Columbia community whose mass shooting it now publicly acknowledges it did not flag.
Footnotes
- 1: Sharon Goldman, "OpenAI releases GPT-5.5 amid a shift to rapid-fire AI updates," Fortune, April 23, 2026.
- 2: OpenAI, "Introducing GPT-5.5," April 23, 2026, https://openai.com/index/introducing-gpt-5-5/.
- 3: Alex Kantrowitz, "OpenAI President Greg Brockman on GPT-5.5 'Spud,' AI Model Moats, and a 'Compute-Powered Economy,'" Big Technology, April 23, 2026.
- 4: Lucas Ropek, "OpenAI releases GPT-5.5, bringing company one step closer to an AI 'super app,'" TechCrunch, April 23, 2026.
- 5: Customer-scale figures from OpenAI's launch material, cited in Goldman, Fortune, April 23, 2026.
- 6: @OpenAIDevs, "With GPT-5.5, Codex now gets more of the job done," X, April 23, 2026, https://twitter.com/OpenAIDevs/status/2047381283358355706.
- 7: Zac Hall, "OpenAI upgrades ChatGPT and Codex with GPT-5.5: 'a new class of intelligence for real work,'" 9to5Mac, April 23, 2026.
- 8: Artificial Analysis, "OpenAI's GPT-5.5 is the new leading AI model," April 23, 2026, https://artificialanalysis.ai/articles/openai-gpt5-5-is-the-new-leading-AI-model.
- 9: Albert Ziegler and Steve Buckley, "GPT-5.5: Mythos-Like Hacking, Open To All," XBOW, April 23, 2026, https://xbow.com/blog/mythos-like-hacking-open-to-all.
- 10: OpenAI, "GPT-5.5 System Card," April 23, 2026, https://deploymentsafety.openai.com/gpt-5-5.
- 11: Ethan Mollick, "Sign of the future: GPT-5.5," One Useful Thing, April 23, 2026, https://www.oneusefulthing.org/p/sign-of-the-future-gpt-55.
- 12: OpenAI Developers, "GPT-5.5 Model," API documentation, April 24, 2026, https://developers.openai.com/api/docs/models/gpt-5.5.
- 13: Carl Franzen, "DeepSeek-V4 arrives with near state-of-the-art intelligence at 1/6th the cost of Opus 4.7, GPT-5.5," VentureBeat, April 24, 2026.
- 14: Theo Browne, comments on GPT-5.5, t3.gg, April 23, 2026.
- 15: "GPT-5.5," Hacker News, thread #47879092, April 23–24, 2026, https://news.ycombinator.com/item?id=47879092.
- 16: Shakeel Hashim, "GPT-5.5 and the broken state of government evals," Transformer News, April 24, 2026, https://www.transformernews.ai/p/openai-shouldnt-be-deciding-if-its-gpt-55.
- 17: Maxwell Zeff, "OpenAI CEO apologizes to Tumbler Ridge community," TechCrunch, April 25, 2026, https://techcrunch.com/2026/04/25/openai-ceo-apologizes-to-tumbler-ridge-community/.
Sources
Analysis · Press Release